
Using this feature with SolrCloud we can create collections for our Sitecore Indexes that are dedicated for handling queries, and will not spend resources on receiving updates instantly. So, these indexes will not be as fast updated as the default NRT replica types, and only receive updated index files from the leader. My hypothesis is that a SolrCloud setup where we use TLOG Replica Types to handle the updates from Sitecore CMs and a few PULL replicate types for the Sitecore CD servers must be optimal for high performance websites.
THE TEST SETUP
For this small test I have it all set up locally on a single machine. This includes Sitecore, Zookeeper and Solr.
STEP 1: SET UP AN ZOOKEPER ENSEMBLE
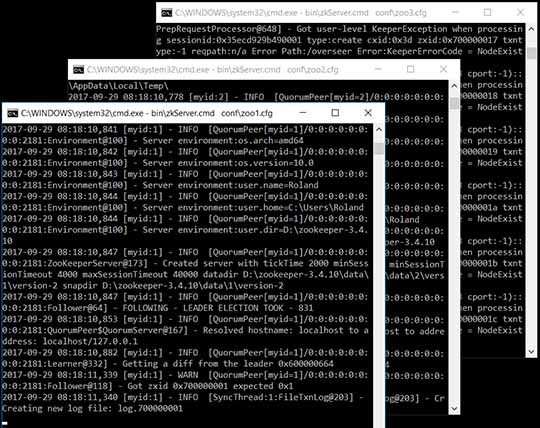
Set up a ZooKeeper Cluster. Not 100% necessary for this test, but for use in a real production environment individual Zookeeper ensembles is highly recommended.
So I have a minimum Zookeeper Ensemble running:
STEP 2: SET UP SOLRCLOUD WITH SITECORE INDEX
I prepared a Sitecore schema following the usual guides for the previous Solr versions, fixing minor complaints such as the “long” type used for _version_ didn’t exist anymore etc. But all in all, minor stuff. I created a new folder for the new Solr configuration prepared for Sitecore 8.2:
STEP 3: START SOLRCLOUD AND PREPARE IT FOR SITECORE INDEXES
Before starting SolrCloud I want to upload my default Sitecore Schema to Zookeeper:
Starting SolrCloud, I point to my Zookeeper Ensemble using the z parameter. Before I do that, I start Solr in cloud mode, and I want to have all my nodes structured nicely on my local drive. I created a folder “sitecore82\node1” under my Solr7 folder, and copy the default solr.xml. Then I can start Solr on cloud mode using:
STEP 4: CREATE THE COLLECTIONS
I decided to add two more nodes to my SolrCloud, simply by copying the current node and rename folders, modifying some configs to get logs into the right folders:
With this I can start node2 and node3 locally as well – same command as with the first node – just another port and pointing the nodes folder:
>bin\solr start -c -z "localhost:2181,localhost:2182,localhost:2183" -s sitecore82\node2 -p 9002 -noprompt
>bin\solr start -c -z "localhost:2181,localhost:2182,localhost:2183" -s sitecore82\node3 -p 9003 -noprompt
Some errors shows up as Solr tries writing to the same general log files. I ignored that for this test. I configured to that each node keeps it’s own log file.

CREATING THE COLLECTIONS
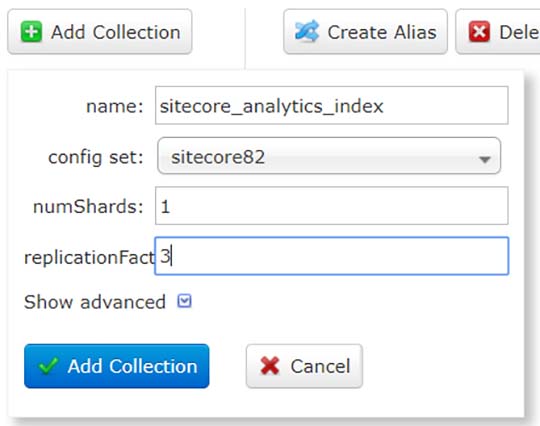
Since I uploaded the configset “Sitecore82” to Zookeeper, it is now visible in Solr Admin for creating collections:
BUT I did not use this for creating the collections. Reason being that I can’t set the replica type. Pretty important, since this what I set out to test. So I did a small script using Solr Collections API so I could specify all the parameters as part of a URL (let me know if you need my simple script for creating all Sitecore collections needed).
Note: As I wanted to have 5 nodes running and know exactly what type of replicas that resides on each node – I created scripts that also handles that part.
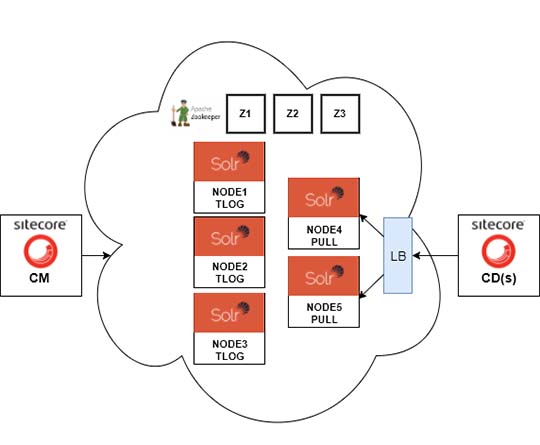
Finally, I got all Sitecore Indexes up as collections. Each collection in 5 replicas on 5 nodes. 3 replicas as TLOGs and 2 as PULL:

STEP 5: DOCUMENT ROUTING AND QUERY ROUTING IN SOLR
By default, SolrCloud decides on what nodes that the different types of replica’s will be created. As mentioned, I handled that by creating the 3 TLOG replicas first, and then used ADDREPLICA command afterward.
Question: So how do I setup an architecture where my Sitecore CD’s servers always query the PULL replica’s?
By default, Solr redirect queries around the cluster. But in this case, we want to query only the specific nodes, where we placed our PULL replicas. That’s what we want for our Sitecore CD servers. Querying specific nodes in the Solr cluster will also be good for performance.
Two options are available:
- Use parameter “preferLocalShards”
This is will make Solr only looking for shards that a local on the server we query. So this should be used with a load balancer so we can query the nodes where we have our PULL replicas running.
- Search specific shards
As part for the query to Solr, we can tell Solr to query specific nodes – that could also be an option
The challenge now is to have Sitecore do one of the above things. Without having to do special things on the Sitecore end, it looks like option 1 will work. Adding this as a default parameter to the default query handler that Sitecore use. This adds a complexity of having an additional load balancer, but that is something we as part of any production setup anyway.
STEP 6: THE FINAL TEST SETUP
The small test setup looks like this:
In the next part of this post I will connect the Sitecore instances, and share the test and result from using this new replica type.

ROLAND VILLEMOES
CTO




